

一,什么是人工智能,如何通俗地理解人工智能?
人工智能、本身就是一款计算机软件,此软件的特别之处就是能够像人一样去思考、学习并且将思考的内容进行决策输出。
那么通俗的讲,人工智能就是可以深度模仿人类的一款智能软件。
通过人工智能的发展,目前人工智能不仅仅是一款软件系统,已经延伸到一种科学技术,也就是一个领域。
那么具体效仿人类的哪些方面?
1,学习能力:人类通过书本学习并且获取知识,大模型通过数据的训练,去进行学习。
2,推理能力:可通过用户的日常喜好,推理出一些用户所需的信息;
3,适应和改进能力:能够通过用户的调教和推演,适应人类的习惯和偏好;
4,人类情感的分析和模拟(附加);
二,人工智能是如何运行的,换个角度,人工智能是如何训练且生成数据的?
人工智能的基础是海量的数据,用不用的模型通过海量的数据训练模型,训练出来的模型也称之为大模型。大模型不仅具有此前被训练的数据能力,并且还有能生成新的数据能力;
1,选择模型 – 例如当下最火的Transformer模型,这里的模型可以理解成一种算法,通过不同的算法将数据训练成不同的模型;
2,训练数据 – 这里的数据来源可以是提供的现有数据,而且模型自身也是有数据收集的能力;
3,大模型部署;
4,大模型应用 – 数据生成(例如生成文本、图片、视频等);
图2-1是大模型的运行模式,大模型整个生命周期实则就是一个反复学习、反复训练(包括应用也属于训练)、的一个闭环过程:
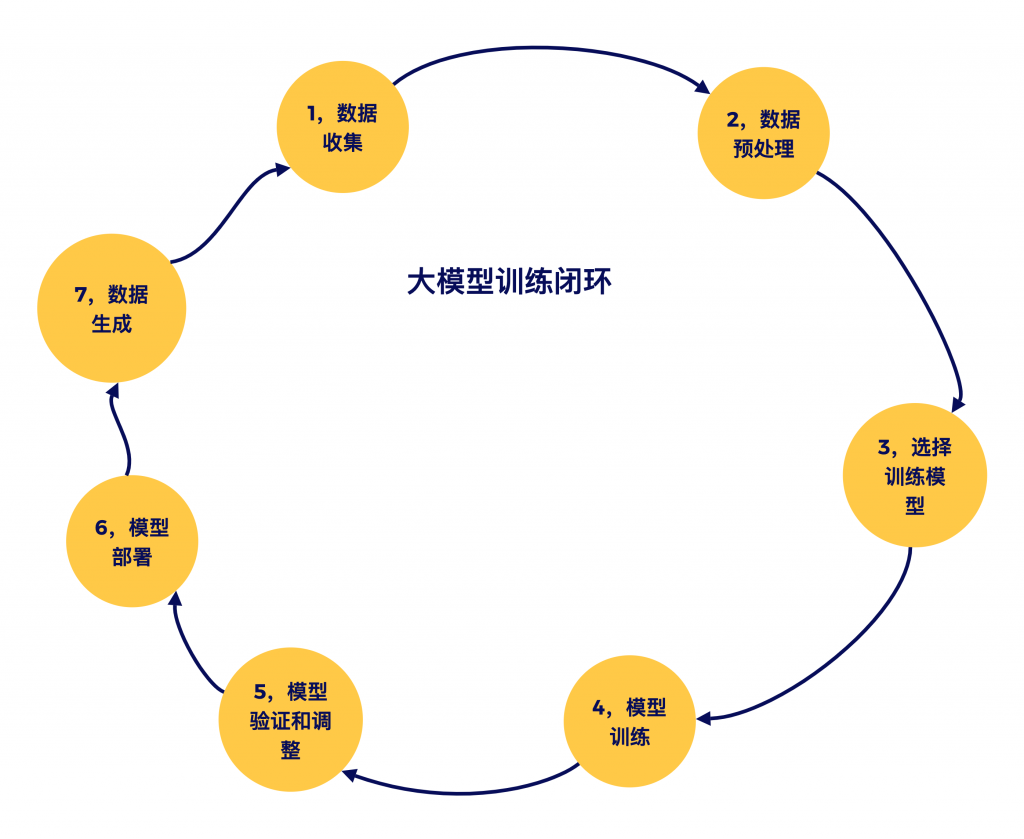
三,人工智能人如何自我学习的?
AI自我学习机制,包含了AI通过海量的数据进行自身学习,还能学习如何“去学习”,也就是说AI可以学习“学习的方法”。
通过不同的数据和方法学习,不断地改进和优化自身的模型。
AI系统能够在不断变化的环境中持续学习和适应,而不会忘记之前学到的知识。
四,多模态人工智能指的是什么?具体的应用有哪些领域?
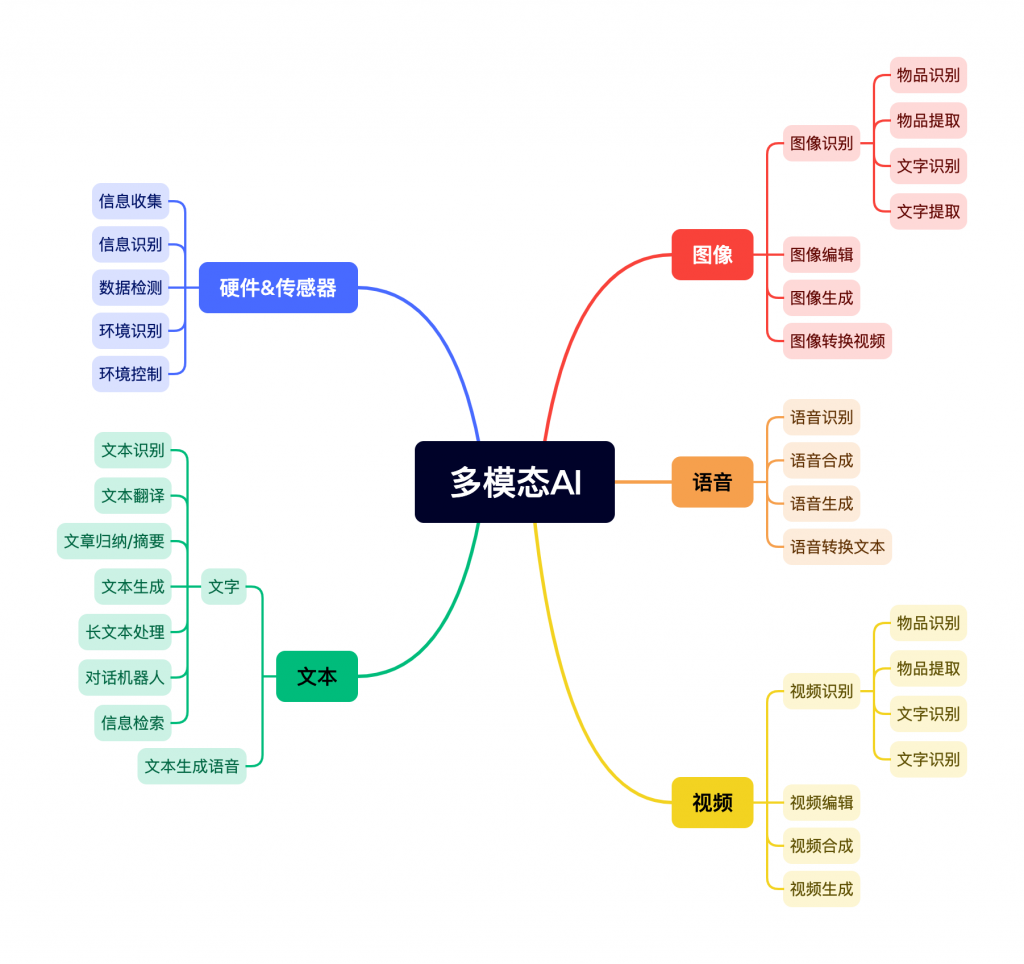
多模态指的是能够处理和理解多种类型的数据和信息源的能力。通俗的讲,就是可以处理各种数据类型的大模型,其包括:
1,文本;
2,图像;
3,音频
4,视频;
5,硬件收集的数据(传感器、激光雷达等);
目前大模型在的应用主要以文本为主,包括文本的摘要,生成、对话机器人等。
多模态大模型的输入端主要还是以PC和手机为主,近几年的发展增加了物联网,车机等硬件去收集数据且进行分析处理。
和多模态人工智能相对的就是单模态人工智能,只能处理一某种类型的数据,例如,图像识别模型只处理图像,文本分析模型只处理文本。也就是说,输入输出的类型是单一的。
单模态人工智能在一个特定的数据类型上进行训练和操作,而不涉及其他类型的数据。
具体分别会对这些数据如何处理,如图4-1:
五,为什么人工智能通过学习会有人类的感情?
人工智能本身没有真正的情感,也不会有真正的情感。只是通过数据和算法模拟出某些情感的表现,以便更好地与人类互动,具体的模拟输出信号可能为以下一些数据源:文本(对话)、音频、视频、物体识别及决策;
通俗地说,大模型通过算法模拟生成有感情的文本(对话)、音频、视频等一些数据,让人类误以为输出的东西有情感,那么大模型就是有情感的,实则大模型本身没有情感。
具体如何模拟情感,也是基于算法和海量的数据,进行深度学习,才有模拟情感的能力,所以大模型在学习的时候,有一项技能叫做“情感分析技术”,可以分析出数据中的情感表现,从而在输出的数据中模拟出人类的情感。
六,大模型中所说的Token是什么,怎么计算的?
token是tokenization的简写,指模型在处理文本时所使用的基本单位。通俗的讲,就是文本处理的大模型通过token来度量大模型的输入输出内容。
具体如何将一个单词/一段文本看做是一个token:
token可以是一个完整的单词、子词,甚至是一个字符,例如:
输入句子“Hello, world!”可能会被分成以下token:
单词级别:[“Hello”, “,”, “world”, “!”]
子词级别:[“Hel”, “lo”, “,”, “wor”, “ld”, “!”]
以上数组中的每一个元素都代表一个token,只是每个大模型的token或许在单词或者子词的规则定义上有所不同,况且还要分世界各种语言。
重点:token 的规则定义也是一种算法,根据大模型的发展,一段话中token的数量越少,内容越精确,那么说明此大模型更厉害;
token具体指的是I/O中的哪个的数量:
大模型中所宣布的token限制,包括输入和输出 token 的总和,也就是I/O加起来的数量。例如输入的Prompt有50个token,大模型输出的content有5000个token,那么它的限制就是5050个token。
输入token对于大模型的影响:
1,输入的Prompt最后分解成token,所以Prompt直接影响大模型的响应速度和大模型输出的质量;
2,处理的token越多,越需要更多计算资源(GPU)和时间;
3,token越多,成本越高;
建议:要精炼Prompt,目前对于AI小白来说Prompt也是需要学习的;
4,token的数量决定了模型的输入和输出的文本长度。
【1】如果输入文本的token数量超过这个限制,超出的部分将不会被处理;
【2】当模型生成的输出token数量达到最大限制时,输出会被截断。模型也会停止生成新的token,输出只包括在限制范围内的部分。
【3】如果是API的话,超出了token数,则回错误或警告信息;
术语:通常如果说有多少K个token,也就是代表1000,4K就代表4000个token的长度;
那么,为什么要大模型要通过token进行训练或者推理呢?
1,可处理复杂的自然语言,包括词汇量、语义多样性、和文本的长度;
2,简化模型的输入,用户输入文本,通过分词技术转换成大模型所需的token,然后将token再输入给大模型进行推理;
3,提高模型的泛化能力,可以理解成,用token进行推理和训练,可以让模型适应或者处理从未训练过的单词,让模型的处理能力更强;
4,提高计算效率,token可以并行处理,提高计算效率;分词化可减少参数、降低训练成本;
5,处理多语言文本,token可在多语言中进行共享,减少多语言模型的词汇表大小;
6,上下文感知嵌入,识别信息后,可通过语境和环境的理解,生成并嵌入一些合理且得当的词语;
为什么说token是大模型的基本单位:
首先从用户输入的文本中,会将文本转换成token,然后大模型通过token进行分析,分析后将内容通过token进行输入,输出后再对token进行组装转换成人类可读的文本,如图6-1所示:
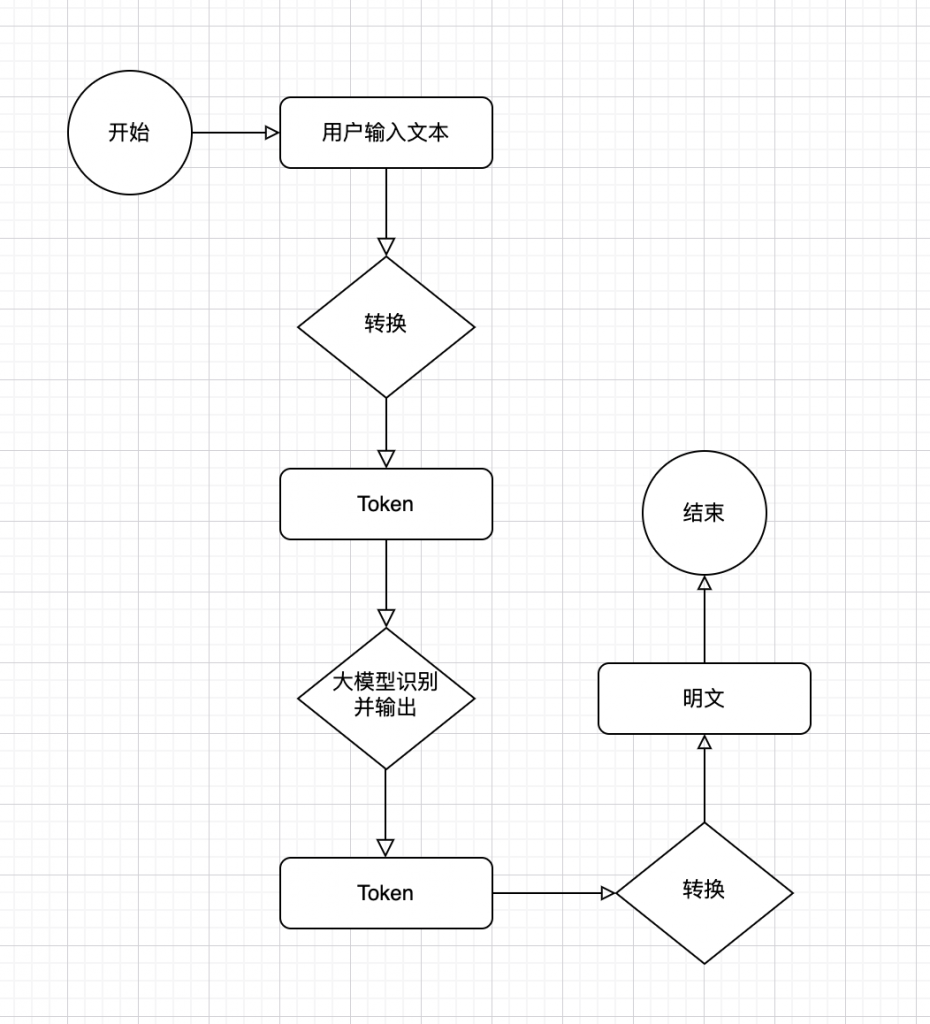
七,那么大模型中通常说的“分词”是什么含义?
分词是一种技术,是将用户输入的文本(字符串)拆解成大模型可以处理的基本单位(token)的过程,叫做分词;
大模型能够处理的基本单位就是token了,所以:
分词是将文本拆解成token的一个过程,它本身是一种技术。
主流的分词技术:
1,WordPiece;
2,Byte Pair Encoding (BPE);
3,SentencePiece;
为什么要进行分词操作?
将用户输入的文本进行分词操作,主要是为了将用户输入的非结构化的文本数据转化为模型能够理解和处理的形式,然后让大模型进行处理;
那么大模型通过输入分词之后的token进行处理事务,有什么好处?
——上,查看条目-六——
八,大模型的量化宽位,4bit、8bit分别指的是什么?
「1」,
4bit和8bit指的是模型权重(或参数)的量化(quantization)位宽。
通俗怎么解释呢,就是指大模型参数的存储位数,位数越小,参数存储所需要的内存资源和模型计算时所需要的带宽资源就对越大,反之亦然。
下表中显示不同宽位的参数存储效果:
32-bit 浮点数 (FP32):传统的高精度表示方法,每个参数占用4字节(32位)。
8-bit 整数 (INT8):量化后的低精度表示方法,每个参数占用1字节(8位),存储需求减小为原来的1/4。
4-bit 整数 (INT4):更低精度的量化表示方法,每个参数占用0.5字节(4位),存储需求减小为原来的1/8。
/**/ /**/ ----------------------------------------------------------------- | 参数个数 | 32-bit 浮点数 (FP32) | 8-bit 整数 (INT8) | 4-bit 整数 (INT4) | ----------------------------------------------------------------- | 100 million | 400 MB | 100 MB | 50 MB | | 1 billion | 4 GB | 1 GB | 0.5 GB | | 10 billion | 40 GB | 10 GB | 5 GB | ----------------------------------------------------------------- /**/ /**/ 1亿、10亿、100亿
「2」,
那么,高精度和低精度的宽位对于大模型有什么利弊?
1,位数越小,越节省大模型的存储空间;
2,位数越小,能耗越低,计算的延迟度更低;
3,位数越小,模型的计算精度越差,误差越大,所以需要在存储和计算效率与模型精度之间找到合适的平衡点;
4,位数越小,部署灵活性,得益于存储空间低和带宽低的优点,所以部署灵活;
量化宽位的过程中,大模型可以在训练和微调时引入量化感知技术,既能保证宽位小,还能保证大模型的误差低。当然这种只是有效缓解的一种结束,毕竟鱼和熊掌不可兼得。
总结:4bit、8bit代表大模型参数的量化宽位后的存储和计算位数、位数越低大模型计算的精度越低,但是有效的缓解了存储和性能压力;
附加:
大模型的量化技术指的是什么?
量化技术是用于减少大模型的存储需求和计算开销的一种技术。也就是将通常所使用的32bit的参数宽位,量化成大模型能够存储和计算的8bit位或甚至于4bit位的一种技术。
量化技术的的步骤:
1,标度:寻找适合目标整数位宽的范围;
2,舍入:将缩放后的数值舍入到最近的整数。例如,将浮点数0.7舍入到整数1。
九,什么是自然语言,NLP又是什么?
1,自然语言指的是人类在生活、生产中需要交流的一种语言,例如汉语,英语等都属于自然语言。
也可以将自然语言处理称之为人工智能,因为它本身就是人工智能的一个分支。
2,NLP,指的是自然语言处理( Natural Language Processing),也就是将计算机中的数字语言处理成人类人能通俗易懂或者说更容易接受的语言,那么自然语言包括:
“机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、情感分析、中文OCR”等方面。
NLP(自然语言处理),是人工智能的一个分支,它让计算机能够理解、解释和生成人类语言。所以NLP有几个概念特征:
(1),能够理解人类的自然语言;
(2),通过理解后,处理并生成人类通俗易懂的自然语言;
为什么能够理解自然语言?
NLP 利用机器学习和深度学习等技术,从大量的文本数据中学习这些规则和模式,通过学习后可以理解并生成。
十,从token就可以延展到上下文窗口(context window)的概念。什么是上下文窗口,上下文窗口的通过什么来表示,具体它的量词是什么?
1,上下文窗口的定义:
[1],上下文窗口指的是模型在一次任务的处理过程中能够“看到”的文本的最大长度。这个长度通常以tokens来表示。这里的看到是指整个大模型在推理过程中可以处理的最大文本长度。
[2],通过token来表示上下文的长度,具体的量词应该是“个”;
[3],任务处理的最大文本长度指的是:(用户)输入的prompt和大模型生成的输出的总和,不是指某一个单一的输入或者输出;
[4],上下文窗口的概念主要是针对自然语言处理领域,例如翻译、文字识别、文档归档、文本生成等功能;
2,上下文窗口和token的关系:
上下文窗口其实就是一个独特领域的token别称,亦可以理解成token;
3,上下文窗口一般如何表示:
输入prompt:2.5K,也就是输入的文本片段占用了2,500 tokens。
模型输出:1.595K,也就是生成的文本最多可以占用1,596 tokens(总和为4,096 tokens)。
十一,大模型中所提到的模型参数100B,100M通常指的是什么?
1,单位:
百万(Million):1M = 1,000,000
十亿(Billion):1B = 1,000,000,000
万亿(Trillion):1T = 1,000,000,000,000
如果是gpt3.0,有175B个参数,也就是它有1750亿个参数;
2,大模型的参数通常形容哪一类AI?
提到大模型的参数,通常是形容通用人工智能(Artificial General Intelligence, AGI),只有通用人工智能才能自主学习并且需要更加复杂的参数结构及网络层数和神经元数量;
2,大模型参数的多少由什么来决定?
[1],模型架构:
[2],连接方式;
[3],其他;
通俗地讲,大模型的参数多少由当前大模型的模型设计和模型的底层架构决定,例如现在OpenAI、Meta等大多都用Google的Transformer架构。
3,大模型的参数能够体现出一个模型的什么特征?
[1],参数越高,表明当前模型能够处理更加复杂的数据,同时也能表达出(输出)更加复杂且精确的数据(内容)。通俗地说,模型参数越大,处理数据的能力、输出的结果越强;
[2],参数越大,需要更多的计算资源(如GPU/TPU)和存储空间来保存和处理模型、那么它的训练时间也会更长。
[3],参数越大,需要有与之相匹配数量的数据进行训练,也就是说,参数越大,就需要更多的数据去训练大模型,这样才能使模型学习更复杂的模式和特征,对应关系。参数大数据少也不行、参数小数据多也是浪费;
[4],参数更多,表示此大模型的学习能力更强,能够学习更复杂的模式,能够提高大模型在处理复杂任务上的表现;
[5],参数越大,能耗越大,越费电;
[6],大参数数据处理能力更强,但是时间更久,对于显卡、存储等芯片需求更大、能耗越大,所以需要合理规划和一些系统算法等技术的优化;
3,模型的参数和训练模型的数据有什么关联?
[1],更大的参数需要更多的数据进行大规模的训练,反之小参数模型不需要大量的数据训练;
[2],如果参数过大,数据过少,模型的学习能力会下降,且遇到新模式的任务在处理上表现更差;
[3],参数数量主要由模型设计和架构决定,而不是直接由数据数量决定。一个模型的参数数量在设计时已经确定,与数据量无关;
[4],数据量影响的是训练效果和模型的泛化能力。更多的数据通常能提升模型的性能,但需要与合适的模型规模(参数数量)相匹配;
4,大模型的参数具体代表什么?
[1],通用大模型就是将世间万物全部当做模型,而不是将某一个单一的事物当做模型,而是所有的事物。那么参数可以理解成所有模型的所有属性+行为的总和,当然大模型的参数定义不会这么简单,以一个笼统的公式表示大模型的参数:
世间万物 * (万物属性 + 万物行为 + 公共属性)
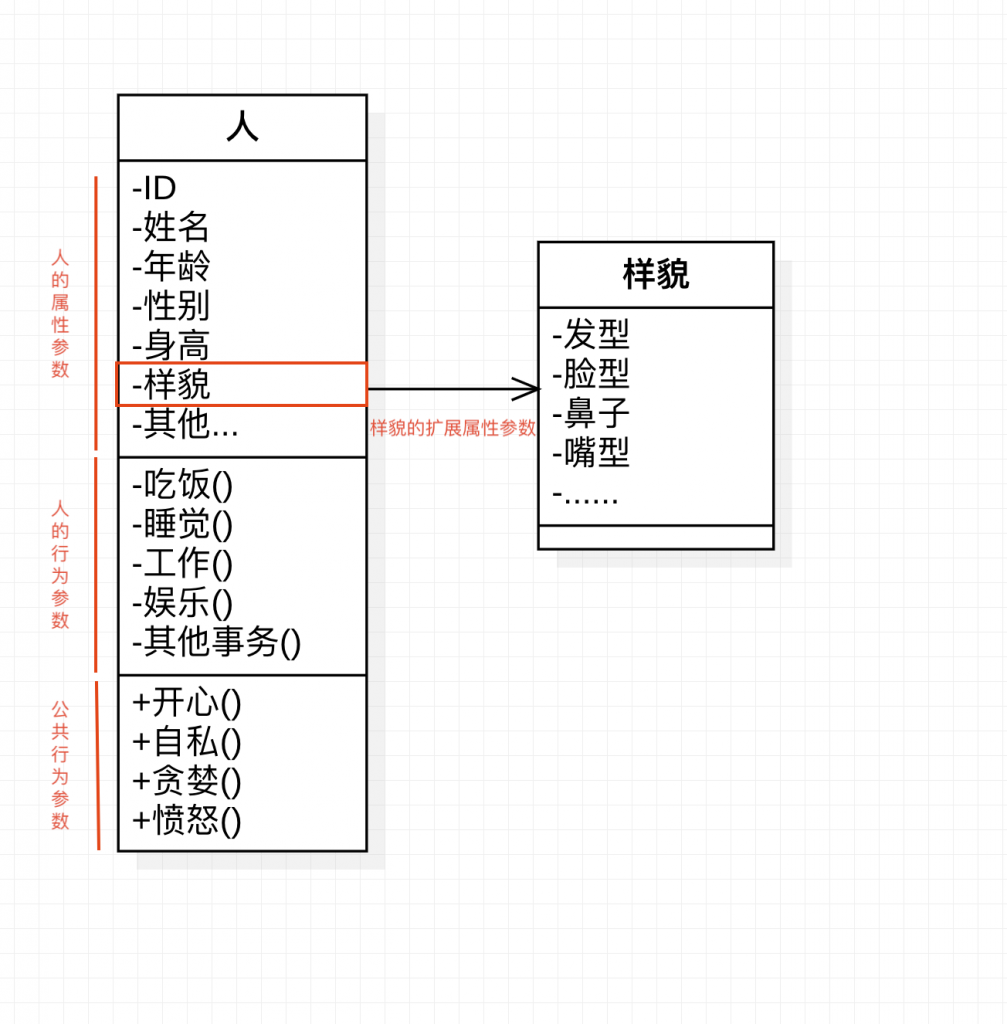
[2],那么如何具象化的表示某一个事物的参数呢?如下图2,具象化的表示了“人”这个物种在自然界/社会中的属性,可以理解成大模型的参数,当然大模型有自己的一套算法去归纳参数,不会这么简单的表现:
[3],图10-1中的每一个属性和行为都可以理解成大模型的一个参数,仅为了方便理解,并非是大模型参数的概念。
十二,通用人工智能(AGI)具体指什么?
1,概念:
通用人工智能(Artificial General Intelligence, AGI)是指具有与人类相当的智能,能够理解、学习、适应和执行任何智力任务的人工智能系统。
通俗的讲:
通用人工智能是一种拟人化的智能系统,可以跟人一样做很多领域的事情、任务,并且最重要的是能够通过学习,适应和理解任何事物和任务。
2,通用人工智能的领域:
通用人工智能其实是一个泛领域的系统,不像单一的系统只能处理一件事情。例如一个场景:上传一张图片,让其识别图片中的文字,并且进行翻译,然后将翻译后的内容进行归纳总结,这就是一个通用人工智能比较经典的案例;
通用人工智能和垂直领域人工智能是两个不同的人工智能系统,一个复杂,一个简单。
3,通用人工智能的特性:
[1],具有自主学习和改进的能力,也就是目前市场上的AI智能助手,大模型可根据自己平时的运用话语及习惯,可自主学习和记录这些习惯,并且根据用户个人的习惯完成制定的任务;
[2],能够适应变化的环境和新出现的挑战,这也就是为什么很多人担心人工智能能够代替人类,因为人类也怕人工智能的适应和学习能力超过人类,那人类的劳动力也将不复存在。
[3],AGI能够理解和回应人类情感,并表现出社交智能,以后也将带有人类的情感;
4,AGI目前的挑战:
1,技术要求高,需要高度复杂和精密的算法;
2,计算复杂,导致需要大量的数据和大量的能耗(CPU,内存等);
3,安全和伦理,如果AGI能够代替人类,那么人类的一切都可以被复制,安全方面有待考虑。伦理方面也需要定制相应的AI法律;
个人思考:目前AGI的发展迅猛,但是门槛较高,只有一些头部的大公司才有资源能够去研发通用人工智能,因为它不仅耗能大,最重要的是数据,需要大量的数据。能耗可以短时间购买,但是数据需要长期的积累和发展存储;
对于以后AGI的应用方面发展的一些思考:
1,AGI以后的商业模式可能主要面向B端用户,也就是企业级用户,可通过对企业级用户进行定制化的AI工具;具体企业可能会涉及到各个领域,电商、社交、学习、游戏等;
2,AGI面向用户级的开放API或许也是它的盈利模式之一,API的接入也算是B端用户使用,不过对于那些没有定制化资金的小微企业和小规模公司也是利好,也是AGI目前的商业模式之一;
3,AGI公司自研的应用,不论是web、App还是VR/AR应用,可通过C端用户订阅,也是它的盈利模式之一。
4,AGI公司租赁多余的算力,例如GPU,存储,或者其他能耗,或许未来会对不同的公司根据纳税的多少限制其电力的使用,那么大公司也可以出租电力给其他创业公司也不无可能;
如下图11-1,介绍通用人工智能和垂直领域人工智能的区别:

十三,谈起大模型,通常说的LLM是什么?
LLM(Large Language Model),大语言模型,是一种能够处理自然语言的大预言模型。
何为自然语言,通俗地讲,就是人类的语言,包括世界各地的各个语种。
所以,大预言模型就是一种能够识别、理解、生成自然语言文本的人工智能模型。
其LLM的最终目标是理解人类的语言->生成人类的语言->模仿人类->代替人类(生产力方向);
如下图12-1,为LLM目前的用途,以后可能会有更多用途及场景:
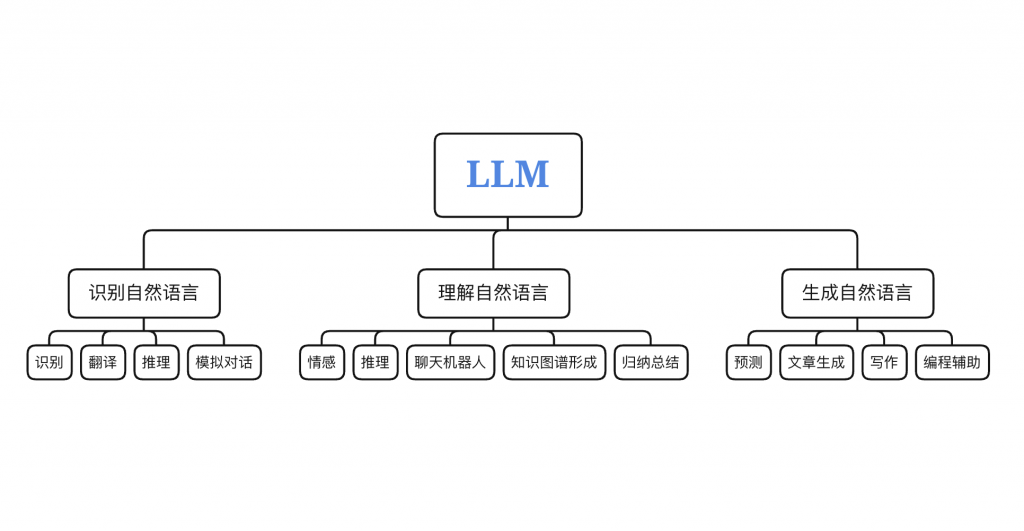
十四,大模型上下文召回怎么理解?
大模型的上下文召回,就是在当前会话中,它能记住你之前说了什么,并结合这些信息来理解你现在说的话,从而做出更准确、连贯的回应。例如:
你 :我想找一个适合家庭出游的地方。
模型 :你可以考虑去杭州,西湖风景优美,适合带孩子玩。
你 :那里有什么好玩的景点吗?
模型:杭州的值得去的景点有xxx,xxx,xxx等;
这里当用户输入了那里,代指的是杭州,那么大模型就会根据当前会话中的记录输出结果,也称之为召回。
十五,大模型的微调是什么意思,目的是什么?
微调的概念:在已有大模型的基础上,用一小部分“专门的数据”继续训练,让模型更符合你的需求。
例如:大模型是一个通用性的员工,但是不懂某一个公司的具体业务和公司对外实现的需求,那么就需要将公司的一些数据(用户数据、业务数据、特定的专业数据等)投喂给大模型进行训练,让大模型更加更贴合特定业务、提高回答质量和一致性,提升服务效率;
微调的目的:让大模型更加更贴合特定业务、提高回答质量和一致性,提升服务效率;
微调的优势:成本低、速度快、效果可控,适用于定制化场景;
十六,AI Agent是什么,怎么理解?
AI Agents可以从字面理解,人工智能代理,就是让AI代理人类去做人类的行为或者动作,从而实现目标。
通俗的理解:AI和一系列工具的结合使用(调用),从而实现人类的某个目标的,这个结合就叫做AI Agent,国内也称之为智能体。
AI Agent的核心:
1,感知:通过接收外部信息(如用户指令、环境数据)来理解当前情况。
2,思考:分析信息,制定计划,决定采取哪些行动、分析调用哪个工具。
3,行动:执行计划,如调用工具、发送请求、操作系统等。
个人附加:
4,输出:输出结果、记忆用户的行为、自主学习;
AI可以记忆用户以往的历史行为、然后通过调用各种工具以及大模型,给出最优的方案。